深度优先搜索
深度优先搜索算法,即Depth First Search,是一种针对图与树的一种图形搜索算法,其基本思想为:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。
举一个例子吧。假设有下面这张图
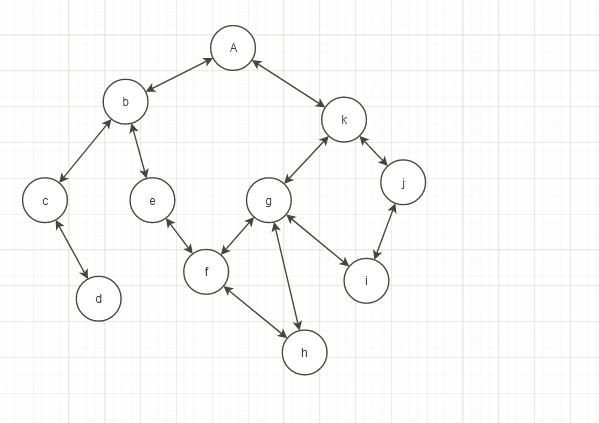
我们要以A为起点来进行遍历,那么实际操作如下
当前在A点,A与b、k连接 ,b、k没有遍历过,前往b 当前走过的路径:A
当前在b点,b与c、e连接,c、e没有遍历过 ,前往c 当前走过的路径:Ab
………
当前在d点,d点无连接,回退到c,当前走过的路径:Abcd
………
当前在b点,b与c、e连接,e没有遍历过 ,前往e ,当前走过的路径:Ab
………
就如同上方描述的方法一般,上方的“当前走过的路径”是一个栈每当遍历一个元素,将其放入栈中,然后遍历下一个与之相邻的元素,假如没有相邻的元素,将这个元素从栈中弹出,然后前往栈顶的那个元素(即回退到上一级)
当我们将整个图像遍历完之后,栈里头的所有元素应该都被弹出了,所以等栈空了,遍历也就完成了。
广度优先
广度优先算法,即Breadth First Search,其基本思想为:从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。
继续举例子,仍然还是那一张图
仍然以A为起点来开始遍历
当前以A为起点,A与bk连接,当前列表:bkA|
当前以k为起点,k与g、j连接,当前列表:gjbk|A
当前以b为起点,b与ce连接,当前列表:cegjb|kA
当前以j为起点,j与i连接,当前列表:icegj|bkA
当前以g为起点,g与fhi连接,i已经在列表中,当前列表:fhiceg|jbka
。。。。。。
依次按照上述遍历方式一直遍历,直到所有的点都在列表之中并被遍历过一遍,当前列表记录了遍历过的元素,“|”符号将列表分隔了一下,最靠近“|”符号左侧的元素即当前正在查找的元素,当其查找完之后,将这个元素挪到“|”符号的右边,代表移出了队列不再遍历这个元素,而在刚刚遍历的过程中,我标红了一行,这一行的遍历过程之中,应该要新加入列表的元素已经在列表之中了,说明新加入的元素已经被遍历过了,“跨边(cross edge)”了,跳过将这个要加入的元素加入即可。当所有的元素都在列表之中的时候,遍历即完成了。
两种遍历方法的对比
内存方面:深度优先的遍历方法遍历过程中只需要储存当前遍历的深度,其占用的内存比较小,而广度优先的遍历方法需要将遍历过程中遍历的每一个元素全部储存下来,其占用的内存较大(这个区别在数据量较小的情况下体现出的差别并不大,但是数据量大起来的话广度优先的算法有概率导致内存不够)
效率方面:深度优先的遍历方法有许多的回溯的操作,而广度优先的遍历算法并没有,所以广度优先的算法在遍历速度上可能快一点。但是其两者在算法的复杂度上相差不大。但是,个人觉得深度优先可能更加适合找到目标为最主要目的的情况,而广度优先可能更加适合以找到最优解为主要目的的情况